How to Mitigate DDoS Attacks for Your Enterprise
Soraxus Assistant
December 25, 2025 • 27 min read

If you want to stop a DDoS attack, you can't wait until you're already under fire. The only way to truly win is to build a defense so deeply into your architecture that most attacks fizzle out before they ever become a real threat. This means moving from a reactive, "break-glass-in-case-of-emergency" mindset to a proactive, always-ready posture.
Building a Proactive DDoS Defense Architecture
Thinking about DDoS mitigation only when the alerts are screaming is a recipe for an outage. A genuinely resilient defense isn't a switch you flip; it's a fundamental part of your infrastructure's DNA. Instead of scrambling during a crisis, you engineer your systems to absorb, filter, and deflect malicious traffic as a matter of course.
The goal here is simple: make your services a fundamentally difficult and unappealing target. By distributing your traffic globally, hardening your core assets, and running protection 24/7, you build a system that’s naturally resistant to the massive volumetric floods and sneaky application-layer attacks that can cripple even a large enterprise.
Distribute Traffic with Anycast Routing
One of the most powerful tools in your arsenal is a global Anycast network. Think of it as a smart, decentralized front door for your services. Instead of a single IP address pointing to one data center, Anycast announces that same IP from dozens of locations around the world. When a user—or an attacker—tries to connect, they're automatically sent to the data center closest to them.
For DDoS defense, this is a game-changer. An attack from a botnet spread across Asia gets absorbed by your network's points of presence (PoPs) in Singapore, Tokyo, and Hong Kong. The malicious traffic is neutralized right at the source, never getting the chance to consolidate into a single, overwhelming flood aimed at your origin servers. For instance, a gaming company could use an Anycast network to ensure that a DDoS attack originating in Europe is handled by scrubbing centers in Frankfurt and Amsterdam, protecting North American players from any latency or disruption.
A proactive defense architecture is designed to handle attacks as a matter of routine, not as a catastrophic event. By distributing traffic and filtering it at the edge, you ensure that only clean, legitimate requests ever reach your critical origin servers.
This diagram shows how these layers work together, starting from the global edge and moving inward to your protected origin.
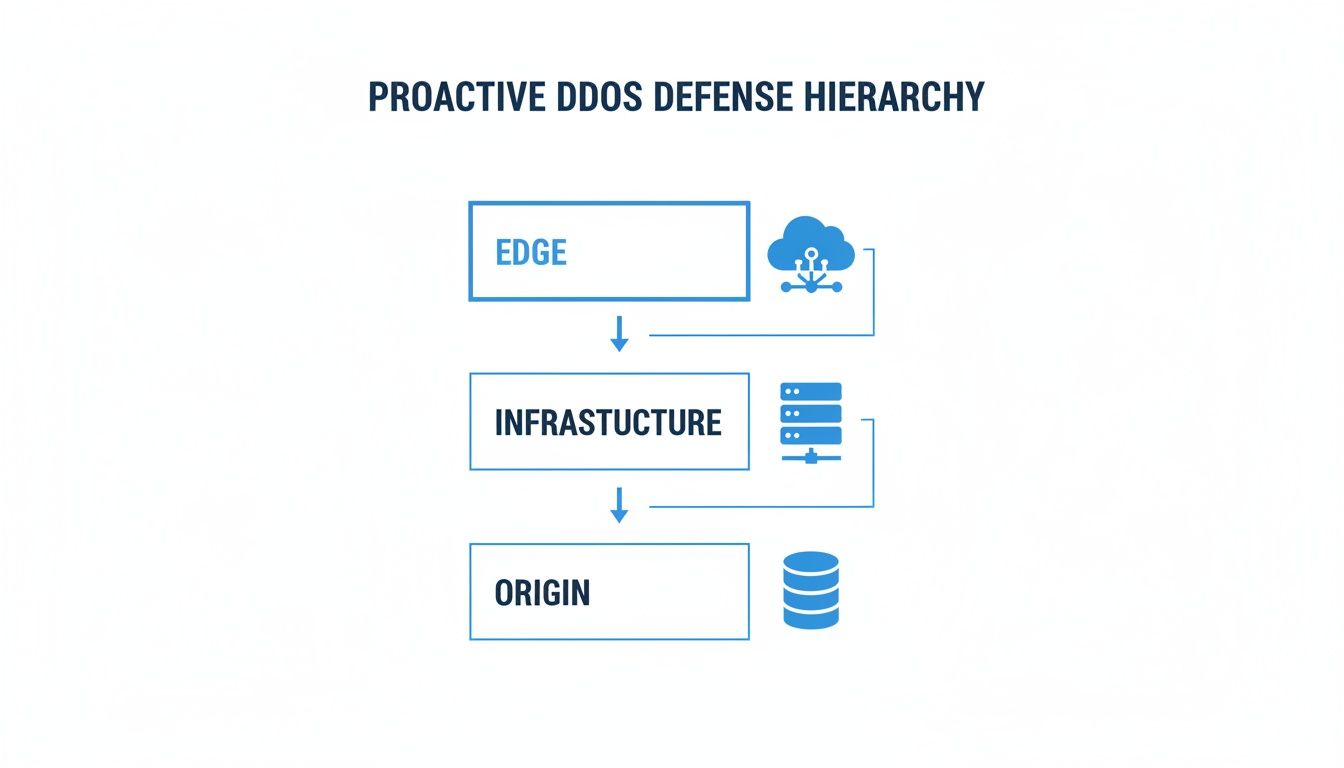
Each layer—Edge, Infrastructure, and Origin—has a specific job in filtering malicious traffic, progressively reducing the burden on your core systems.
To make this more concrete, here's a breakdown of the key architectural layers you need to consider.
DDoS Mitigation Architecture Layers
| Layer | Objective | Key Technologies & Strategies |
|---|---|---|
| Edge Layer | Absorb and filter massive volumetric attacks as close to the source as possible. | Anycast Routing, Global Scrubbing Centers, Rate Limiting, Geo-Blocking, IP Reputation Filtering. |
| Infrastructure Layer | Protect core network components and ensure service availability under stress. | Firewalls, Load Balancers, Intrusion Prevention Systems (IPS), Network Access Control Lists (ACLs). |
| Application/Origin Layer | Defend against sophisticated L7 attacks that mimic legitimate user traffic. | Web Application Firewalls (WAF), API Gateways, Challenge/Response Mechanisms (e.g., CAPTCHA), Server Hardening. |
By layering these defenses, you create a system where each component reinforces the others, making it exponentially harder for an attacker to succeed.
Embrace Always-On Protection
The old model of "on-demand" mitigation—where you manually reroute traffic to a scrubbing service after an attack is detected—is dangerously slow. An always-on mitigation service routes all your traffic through a global network of scrubbing centers continuously. This means protection is active 24/7/365, not just during an emergency.
The benefits are immediate and obvious:
- Sub-second Mitigation: Malicious traffic patterns are caught and blocked in real-time, often before your monitoring systems can even fire an alert.
- No Human Delay: You eliminate the critical minutes it takes for an engineer to verify an attack and trigger a traffic diversion—minutes when your service would otherwise be offline.
- Smarter Detection: The system constantly learns your baseline traffic patterns, making it far easier to spot the subtle anomalies that signal a sophisticated attack.
Let's be clear: you can't fight modern volumetric attacks with on-premise hardware anymore. Telemetry from the first half of 2025 showed the average large botnet grew by about 67% in just three months, and they can launch floods that will instantly saturate any enterprise-grade internet connection. With 78% of attacks ending within five minutes, the automated speed of an always-on response is what determines whether you have a brief anomaly or a full-blown outage.
Harden Your Origin Servers
Even with a world-class network filtering traffic for you, your origin servers still need to be locked down. Hardening your core infrastructure is about shrinking the attack surface, giving malicious packets that might slip through nowhere to go.
Here are a few practical things you should be doing:
- Tune Your Firewalls: Be ruthless with your ingress and egress rules. If you only run a web service on ports 80 and 443, there is zero reason for ports like FTP (21) or SSH (22) to be open to the public internet. Block everything by default and only open what is absolutely necessary.
- Use Intelligent Load Balancing: A good load balancer does more than just distribute traffic; it prevents any single server from becoming a bottleneck. This is crucial for surviving application-layer attacks that target a specific resource, like a CPU-intensive search query on your e-commerce site.
- Block Unnecessary Regions: If your customers are all in North America and Europe, why accept traffic from other continents? Strategic geo-blocking at the edge or firewall is a simple and surprisingly effective way to eliminate a massive volume of automated threats.
These origin-level controls are the final, critical piece of your defense. For a deeper look at securing your core systems, it's worth reviewing these essential network security best practices.
Defending Against Application-Level Attacks
The big, noisy volumetric floods tend to get all the attention, but the real danger is shifting toward smarter, more insidious attacks. The application-layer (L7) attacks we're seeing now are designed to look exactly like legitimate user traffic, which makes them incredibly difficult to spot. Instead of just trying to clog your pipes with bandwidth, these attackers are aiming to quietly exhaust your server resources—CPU, memory, and critical application processes—by hammering specific, computationally expensive functions.
Fighting this kind of assault requires a completely different mindset. You can't just absorb the traffic and hope for the best. You have to intelligently inspect every request to separate your genuine customers from the malicious bots hiding in plain sight. A solid L7 defense is all about deeply understanding your application's logic and deploying precise controls that neutralize threats without ever disrupting the user experience.

Tune Your Web Application Firewall
Think of your Web Application Firewall (WAF) as the primary shield against these L7 attacks. But here’s the thing: a WAF with default, out-of-the-box rules is like a locked screen door. It'll stop the most obvious intruders, but it won't offer much resistance to a determined attacker. It's the meticulous, ongoing tuning that transforms a generic WAF into a formidable defense.
This means getting your hands dirty and creating custom rules that actually reflect how your application is supposed to work. For example, if you have an API endpoint like /api/v1/submit_form that should only ever receive POST requests, why allow anything else? Create a specific rule that blocks all GET, PUT, or DELETE requests to that URI. A simple, targeted rule like that can shut down an entire class of potential attacks in an instant.
Beyond that, a modern WAF has to do more than just simple signature matching. It needs to be smart enough to spot behavioral anomalies. Let's say a single IP address suddenly starts hitting every product page on your e-commerce site at a rate of 100 pages per second. That’s not a human shopper. An intelligent WAF flags this behavior and can automatically present a challenge (like a CAPTCHA) or temporarily block the source before it does any damage.
Implement Granular Rate Limiting
Rate limiting is a foundational technique, but its real power is in the details. Applying a single, site-wide request limit is a blunt instrument that can easily penalize your legitimate users during a real traffic spike. The right way to do it is to apply different, more granular limits based on the specific resource being accessed and, if possible, the identity of the user.
Here are a few practical scenarios:
- Login Endpoints: The login page is a magnet for credential stuffing bots. A practical approach is to implement a strict rate limit of 5 attempts per minute per user account and 10 attempts per minute per IP address. This makes brute-force attacks painfully slow and inefficient for the attacker.
- Search APIs: A public search API can be easily abused to scrape data or overload your database. A reasonable starting point is 60 requests per minute per API key, which ensures fair use for developers without crippling the service.
- Shopping Carts: The "add to cart" function can be surprisingly resource-intensive. You could limit this action to 10 times per minute for a single user session, which effectively stops bots from creating millions of abandoned carts just to exhaust your server memory.
This contextual approach is what makes it work. By tying limits to sessions, user IDs, or API keys instead of just IP addresses, you can neutralize abusive traffic with surgical precision.
Secure Your APIs and Manage Bots
APIs are the backbone of modern applications, which also makes them a frequently overlooked attack vector. Attackers love them because they often have direct lines to your most critical backend processes and databases. Securing them properly requires a multi-pronged strategy: strong authentication, strict schema validation, and, most critically, sophisticated bot management.
An effective L7 defense cannot rely on a single control. It requires a layered approach combining a tuned WAF, intelligent rate limiting, and advanced bot management to accurately distinguish between human users and malicious automated traffic.
Advanced bot management systems are a game-changer. They analyze subtle signals—like mouse movements, browser fingerprints, and even the timing between requests—to tell the difference between a human and a script. This allows you to automatically block malicious bots while still letting the good ones, like search engine crawlers, do their thing.
If you're only focused on network-level defenses, you're leaving a huge gap. In fact, attackers often combine volumetric floods with these sneaky application attacks in what are known as multi-vector attacks. Recent analysis found that API-targeted attacks can cause outages 4.2 times longer than traditional network attacks while using 90% less traffic. That statistic alone proves that a strong application defense is absolutely essential for maintaining uptime. You can learn more about how multi-vector attacks are changing the threat landscape.
Implementing Rapid Threat Detection and Alerting
When you're dealing with a DDoS attack, every second counts. The real damage—the downtime, the customer frustration—happens in the gap between the attack starting and your team actually doing something about it. Having powerful defenses is one thing, but if you can't activate them instantly, you're already behind. This is why you need a rock-solid system for real-time threat detection and alerting that takes the guesswork out of the equation.
This goes way beyond simple server health pings. You need to be watching a very specific set of metrics that act like an early warning system. The moment these numbers stray from your established baseline, it needs to kick off an immediate, automated response—notifying the right people and engaging your defenses before a human even has to touch a keyboard.

Monitoring the Right Metrics
A smart detection strategy is all about tracking the right signals across both your network and application layers. If you focus on the right things, you can spot an attack as it's building, not after your services have already ground to a halt.
Here are the non-negotiable metrics your monitoring system has to track:
- Network Throughput (bps/pps): This is the classic. A sudden, massive spike in bits per second (bps) or packets per second (pps) is the tell-tale sign of a volumetric L3/L4 attack. Your monitoring needs a clear baseline of what "normal" looks like so it can flag major deviations.
- Requests Per Second (RPS): For L7 attacks, RPS tells the real story. You can be flooded with seemingly legitimate HTTP requests that will crush your web servers long before your network bandwidth even flinches. A sudden jump from a baseline of 500 RPS to 50,000 RPS for a specific API endpoint is a clear indicator of an attack.
- CPU Load and Memory Usage: Application-layer attacks are designed to make your servers sweat. A sudden jump in CPU or memory consumption on your origin servers is a huge red flag that you're facing a resource-exhaustion attack.
- Application Error Rates: Keep a close eye on your HTTP 5xx server errors. When your application starts throwing errors under load, it's often a sign that a targeted attack is succeeding at chewing up your backend resources.
By tracking these indicators together, you get a much clearer picture of your system's health, which is crucial for telling the difference between a flash sale and a malicious flood.
Setting Intelligent Alert Thresholds
The whole point of alerting is to flag real threats without drowning your team in noise. If your on-call engineers get pinged with dozens of false alarms every day, they're going to start ignoring them. This is where you have to get smarter than static thresholds.
Forget setting a simple limit like "alert me if traffic hits 1 Gbps." That's old-school thinking. Traffic on a Tuesday morning looks nothing like traffic on Black Friday, and your system needs to understand that context.
The most effective alerting systems don't just use static numbers; they use machine learning to understand your application's normal rhythm. An alert should fire when behavior is anomalous, not just when it's high.
This approach cuts down on false positives dramatically. It means that when an alert actually fires, it’s a real event that needs immediate attention.
Automating Mitigation and Notifications
Once you've detected a credible threat, the response has to be instant. Humans are simply too slow. Automation is the only way to get to sub-second mitigation.
This is where integrating your monitoring system with your mitigation provider’s API is a total game-changer. For instance, an automated system can detect an unusual spike in traffic to a login API and use an API call to instantly apply a more aggressive WAF rule that challenges suspicious requests, shrinking your response time from minutes down to milliseconds.
At the same exact time, your alerting system needs to hit the right people on the right channels.
- Critical Alerts: A confirmed, high-severity attack should trigger a PagerDuty notification or an SMS message straight to the on-call network engineering team. No delays.
- Warning-Level Alerts: For anomalies that need a look but aren't service-impacting yet, route them to a dedicated #security-alerts Slack channel. This keeps the broader team in the loop without waking someone up at 3 a.m.
This tiered approach ensures critical events get the urgent response they need while everyone stays informed. By combining intelligent monitoring with automated mitigation triggers, you build a response system that's fast enough to shut down DDoS attacks before your users even know they happened.
Crafting Your Incident Response Playbook
When a DDoS attack hits, the only thing separating a calm, methodical response from total chaos is a well-defined playbook. This isn't just some document you write and forget about; it's the living, breathing set of instructions that becomes muscle memory for your entire organization.
A solid playbook turns a potential catastrophe into a managed event. It takes the guesswork out of a high-stress situation, making sure everyone knows their role, who to call, and what to do next. Under fire, people don't magically rise to the occasion—they default to their training. This is that training.
Who Does What? Defining Roles and Responsibilities
First things first: you need to decide who is responsible for what. When the alerts go off, the last thing you want is confusion or people stepping on each other's toes. A small, empowered incident response team is your best bet for moving fast.
Here are the core roles you’ll want to assign:
- Incident Commander: This is your quarterback. They're the single point of contact leading the response, making the tough calls, and keeping everyone coordinated. It's not always the most senior person in the room, but it's the one who can best manage a crisis.
- Technical Lead: This is your hands-on expert. They’re the one digging into the attack data, working with your mitigation provider to filter traffic, and confirming that services are back online.
- Communications Lead: This person owns the narrative. They handle all updates, both internally to leadership and externally to your customers. Their job is to deliver clear, accurate information without causing a panic.
With these roles defined ahead of time, you can assemble your war room in minutes, not hours.
Setting Up Clear Communication and Escalation Paths
Your playbook needs to be crystal clear about how information flows during an attack. This covers everything from internal Slack channels to public-facing status page updates. A practical step is to have pre-written, pre-approved templates ready to go. You don't want to be wordsmithing a customer announcement while the site is down.
Just as critical is a formal escalation path. What's the protocol if the on-call engineer can't get a handle on the issue in 15 minutes? The playbook must spell out exactly who they contact next, and who that person contacts, all the way up the chain. This prevents an incident from stalling out.
A documented response plan isn't about creating red tape; it's about building speed. By pre-defining roles, communication channels, and technical procedures, you empower your team to act decisively and execute flawlessly under extreme pressure.
Your playbook should also get into the technical weeds. It needs documented, step-by-step instructions for critical actions—like how to apply an emergency WAF rule, divert traffic to scrubbing centers, or block a specific attack signature. This is especially vital for niche industries; for instance, the response detailed in our guide on DDoS protection for game servers involves steps you wouldn't see in a typical SaaS environment.
Don't Just Write It, Rehearse It

A playbook that sits on a shelf is just a theory. You have to test it.
The best way to do this is with regular tabletop exercises. Get your response team in a room and walk them through a simulated attack. Give them a real-world scenario: "We're seeing a massive flood of UDP packets from thousands of IPs, and our game servers are timing out. Go."
These drills are invaluable. They do three crucial things:
- They build the "muscle memory" your team needs to act instinctively.
- They expose the weak spots and gray areas in your playbook so you can fix them.
- They get your technical, communications, and leadership teams comfortable working together under pressure.
In a DDoS attack, preparation and speed are the only things that matter. Recent data shows that a rehearsed response plan significantly cuts down outage times and recovery costs. Think about it: with 78% of attacks burning out within five minutes, your ability to react instantly is everything. A practiced playbook, combined with an always-on solution, ensures you can activate your full defenses in under two minutes and ride out those short, intense attacks without your customers ever noticing.
Choosing the Right DDoS Mitigation Partner
Let's be blunt: you can't fight a terabit-scale DDoS attack on your own. No matter how well-architected your internal infrastructure is, it was never designed to absorb the kind of volumetric floods that are now routine. This is exactly why a specialized DDoS mitigation provider isn't a luxury—it's a core component of any serious defense strategy.
Picking the right partner is a huge decision, one that goes way beyond a simple price comparison. You’re essentially handing them the keys to your online availability and, by extension, your reputation. The goal is to find a provider that operates like a genuine extension of your security team, bringing not just powerful tech to the table but also the seasoned expertise needed to handle a relentless threat.
First Things First: Raw Network Capacity and Global Reach
The very first question you should ask is about a provider's raw capacity to absorb an attack. This is measured in Terabits per second (Tbps) and tells you the total volume of junk traffic their network can soak up before it starts to buckle. A provider with a small network can easily be knocked over by the same attack they're supposed to be protecting you from.
You need to see a global network with serious capacity—we're talking well into the multi-terabit range. As a benchmark, a robust provider should maintain over 1.5 Tbps of dedicated mitigation capacity, which is the kind of muscle required to handle today's monstrous volumetric attacks without breaking a sweat.
Just as important is where their scrubbing centers are located. These specialized data centers are where the magic happens—filtering out malicious traffic while letting the good stuff through. A provider with dozens of globally distributed points of presence (PoPs) can mitigate an attack closer to its source. This dramatically cuts down latency for your legitimate users and makes the entire response faster and more effective.
Put Their Service Level Agreement Under a Microscope
A provider’s promises are only as good as their Service Level Agreement (SLA). This is the legally binding document where marketing fluff ends and concrete commitments begin. You absolutely have to read the fine print.
Here’s what to zero in on within the SLA:
- Time-to-Mitigate: This is the big one. It’s the maximum guaranteed time between an attack being detected and mitigation kicking in. Look for guarantees measured in seconds, not minutes. Every second counts.
- Performance During an Attack: The SLA should be crystal clear about the level of network performance you can expect while an attack is being mitigated. Will your genuine traffic get bogged down by high latency or packet loss? Get specifics.
- Uptime Guarantee: A solid SLA will promise high uptime, typically 99.99% or higher, and spell out the penalties if they don't deliver.
An SLA isn't just a legal formality. It's a direct reflection of a provider's confidence in their own technology and operational discipline. If the promises are vague, that’s a major red flag. Demand specific, measurable commitments.
Always-On vs. On-Demand: A Critical Choice
DDoS mitigation services generally come in two flavors, and picking the right model for your business is crucial.
- Always-On Mitigation: With this approach, all your traffic is continuously routed through the provider's global network, 24/7. Malicious traffic gets filtered in real-time before it ever touches your infrastructure. This is the gold standard for any mission-critical application where even a few seconds of downtime is a disaster.
- On-Demand Mitigation: Here, you only divert your traffic to their scrubbing centers after you’ve detected an attack. While it might seem cheaper upfront, it introduces a dangerous delay between detection and response. That delay is your window of vulnerability.
Considering that a staggering 78% of DDoS attacks last less than five minutes, the built-in lag of an on-demand service is a massive risk. For most enterprises, an always-on solution delivers vastly superior protection and, frankly, peace of mind. For teams managing their own hardware, understanding how to integrate these services is critical, which is why our guide on securing dedicated servers with DDoS protection is such a useful read.
Don't Settle for Anything Less Than Full L3–L7 Protection
Finally, make sure any partner you consider can handle the entire spectrum of threats. Big, noisy volumetric attacks at the network layer (L3/L4) are just one piece of the puzzle. The really sophisticated attackers are increasingly using clever application-layer (L7) attacks that perfectly mimic legitimate user traffic to silently exhaust your server resources.
Your partner must have a proven, multi-layered defense that can stop both. This means they need:
- Volumetric Absorption: The raw network scale to soak up huge floods.
- Protocol Validation: The intelligence to inspect packets and instantly drop anything malformed or non-compliant.
- Advanced WAF Capabilities: A smart Web Application Firewall that can block sophisticated L7 attacks like SQL injection and cross-site scripting.
- Behavioral Analysis: Machine learning and other advanced techniques to tell the difference between a real human and a malicious bot.
Choosing a partner ultimately comes down to finding the right mix of raw power, global reach, contractual guarantees, and deep technical expertise. The table below can serve as a helpful checklist during your evaluation process.
DDoS Mitigation Partner Evaluation Checklist
When you're vetting potential providers, it's easy to get lost in marketing jargon. Use this checklist to cut through the noise and focus on what truly matters for protecting your business.
| Evaluation Criterion | What to Look For | Why It Matters |
|---|---|---|
| Network Capacity (Tbps) | A multi-terabit global network (e.g., 1.5+ Tbps). Ask for their total capacity, not just a single PoP. | Ensures they can absorb massive volumetric attacks without their own infrastructure becoming overwhelmed. |
| Global Scrubbing Centers | Dozens of geographically diverse Points of Presence (PoPs) across major continents. | Mitigates attacks closer to the source, reducing latency for your legitimate users and improving response time. |
| SLA: Time-to-Mitigate | A guaranteed, contractually-backed time measured in seconds (e.g., under 10 seconds). | Every second of downtime costs you money and reputation. A fast, guaranteed response is non-negotiable. |
| SLA: Performance Guarantee | Specific metrics for latency and packet loss during mitigation. Avoid vague "best effort" language. | Your service must remain usable for legitimate customers even while you're under attack. |
| Mitigation Model | "Always-on" for mission-critical services. Traffic is always routed and inspected in real-time. | Eliminates the dangerous delay inherent in "on-demand" models, which can leave you exposed for critical minutes. |
| L3–L7 Protection | A unified solution that defends against both volumetric (L3/L4) and application-layer (L7) attacks. | Attackers use a mix of techniques. Your defense must be able to counter everything from simple floods to complex bot attacks. |
| Support & Expertise | 24/7 access to a dedicated Security Operations Center (SOC) with DDoS experts, not just a general support line. | When you're under attack, you need to talk to an expert who can make immediate, intelligent adjustments—not a ticket-taker. |
By carefully weighing these criteria, you can move beyond a simple feature comparison and find a true partner who will stand with you on the front lines, making sure your business stays online no matter what attackers decide to throw your way.
Common Questions About DDoS Mitigation
When you're in the trenches building out a DDoS defense strategy, the same questions tend to pop up again and again. Let's tackle some of the most common ones I hear from enterprise teams.
What Makes These Attacks So Damn Hard to Stop?
The real headache with DDoS attacks is their brute-force, "loud and proud" nature. This isn't a stealthy infiltration; it's a full-frontal assault designed to overwhelm you.
The difficulty really boils down to three things:
- Sheer Volume: We're talking about traffic from millions of hijacked devices—a botnet—all hitting you at once. It's a firehose of data aimed at a garden hose connection.
- Scattered Sources: The attack isn't coming from one place. It's from countless IP addresses all over the world, so playing whack-a-mole by blocking individual IPs is completely futile.
- Deceptive Traffic: The smarter application-layer (L7) attacks are engineered to look almost exactly like legitimate user activity. They request web pages and interact with your app just like a real customer would, making them incredibly tough to spot and block without impacting actual users.
At the end of the day, you're tasked with filtering out millions of malicious packets while ensuring every single legitimate customer request gets through flawlessly. It’s a needle-in-a-haystack problem, but the haystack is on fire.
How Fast Do I Really Need to Respond?
Seconds. Not minutes.
Modern DDoS attacks are often "burst" attacks—short, incredibly intense floods designed to knock you offline before a human engineer can even get paged. In fact, recent reports show that 78% of DDoS attacks are over in less than five minutes. Many are over in 60-90 seconds.
If your game plan relies on someone getting an alert, logging in to confirm it, and then manually switching traffic over to a mitigation service, the fight is already over. You lost. The attack will have done its damage and moved on before your defenses are even online.
This is exactly why automated, always-on protection has become the non-negotiable standard for any service that can't afford to go down.
Can't My Firewall Just Handle This?
In a word, no. A firewall is a critical piece of your security stack, but it’s the wrong tool for this job. Think of it like using a scalpel to stop a tidal wave.
Firewalls are stateful devices built to enforce access rules, not to absorb a tsunami of malicious traffic. A big volumetric attack will completely saturate your internet pipe long before that traffic even gets a chance to be inspected by your firewall. For example, a 100 Gbps UDP flood will overwhelm a 10 Gbps internet connection instantly; the firewall never even sees most of the attack traffic.
On top of that, firewalls just don't have the deep packet inspection smarts to pick out those sneaky application-layer attacks that mimic real user behavior. They play a role, but they are not a DDoS solution.
What's the Difference Between an L3/L4 and an L7 Attack?
Knowing the difference is absolutely critical because you have to defend against both. The layers refer to the OSI model, which is just a way of categorizing how networks function.
- L3/L4 (Network/Transport Layer) Attacks: These are the big, dumb, brute-force floods. Imagine a thousand trucks dumping gravel onto the highway that leads to your office. Nothing gets in or out. Attacks like UDP floods and SYN floods are designed purely to clog your network bandwidth and server connections.
- L7 (Application Layer) Attacks: These are the clever ones. Instead of blocking the highway, they send thousands of people into your lobby to ask the receptionist complicated questions all at once. Your staff gets overwhelmed and the business grinds to a halt. An HTTP flood, for instance, can repeatedly request a search query or a complex report, maxing out your server's CPU and memory until it crashes.
A truly resilient defense has to handle both the brute-force floods and the sophisticated application attacks—often at the same time.
At Soraxus, we live and breathe this stuff. Our enterprise-grade, always-on DDoS mitigation is built to stop any attack, of any size or complexity, in seconds. With a global network capacity exceeding 1.5 Tbps and intelligent L3–L7 filtering, we absorb the flood and neutralize the threats before they even know you’re there. Protect your uptime and your reputation by checking out our DDoS mitigation services.


