Explore enterprise infrastructure solutions for scalable performance and security
Soraxus Assistant
January 21, 2026 • 26 min read

So, what exactly are we talking about when we say "enterprise infrastructure solutions"?
Think of it this way: you could rent a desk in a coworking space, or you could build your own corporate headquarters. While the coworking space is convenient, your company’s security, performance, and even brand image are subject to the building's rules and the behavior of other tenants. Building your own HQ, on the other hand, gives you complete control over every single detail, from the foundation to the security systems.
That’s the difference. Enterprise infrastructure is your purpose-built digital headquarters, engineered for unmatched control, security, and performance—a world away from the one-size-fits-all model of the public cloud.
Where Off-the-Shelf Solutions Fall Short
For any business where speed and uptime are tied directly to the bottom line, generic, shared infrastructure is a massive gamble. The "noisy neighbor" effect is a real problem—one user's massive resource spike can suddenly bog down your application, creating a terrible experience for your customers.
Imagine you're running a massive e-commerce platform during a flash sale, or a SaaS company providing a critical video conferencing service. A slowdown isn't just an inconvenience; it's lost revenue and a damaged reputation. Enterprise solutions are designed from the ground up to eliminate these risks by providing the dedicated, raw power needed to guarantee a consistent user experience and meet strict service-level agreements (SLAs).
The Core Pillars of Enterprise Infrastructure
This purpose-built strategy rests on three foundational pillars, each addressing a critical weakness of standard hosting. To support an application that absolutely cannot fail, you need all three.
- Performance: This is all about dedicated, uncontended resources. For instance, a gaming company running a fast-paced multiplayer shooter needs bare metal servers with the latest CPUs to minimize latency and ensure fair, responsive gameplay for its players. You just can't get that same reliable, low-latency performance from a virtualized server sharing hardware with dozens of other unknown workloads.
- Security: This means building a hardened perimeter with defense in depth. A financial services app processing sensitive transactions can’t afford to be vulnerable. It demands robust, always-on DDoS mitigation to fend off attacks that could otherwise take it offline and shatter customer trust in an instant.
- Scalability & Control: This is about having the freedom to grow on your own terms, without vendor lock-in. A managed service provider (MSP) can use colocation to install its own custom hardware in a secure, carrier-neutral data center, giving them total command over their network and architecture as they scale their client offerings.
The market reflects this growing need for powerful, dedicated environments. The global data center infrastructure market was pegged at USD 68.2 billion in 2024 and is on track to hit USD 234.8 billion by 2034, rocketing forward at a 13.4% compound annual growth rate. This boom is fueled by the insatiable demands of AI, large-scale SaaS, and other heavy-duty workloads.
At its heart, an enterprise solution is about eliminating uncertainty. It replaces the unpredictable nature of shared resources with the cast-iron reliability of a dedicated environment, engineered for a specific, mission-critical job.
Ultimately, choosing enterprise infrastructure is a strategic move to put reliability and control first. It’s an investment in a digital foundation that’s strong enough to support your most critical business goals, making sure your services are always fast, secure, and online. By looking into a range of enterprise-grade services, companies can hand-pick the right components to build their ideal digital headquarters.
The Building Blocks of High-Performance Infrastructure
To build a truly powerful enterprise infrastructure, you first have to understand what it's made of. Each component has a specific job, and when you put them together the right way, they form a rock-solid, high-speed foundation for your most important applications. Think of it less like buying a computer off the shelf and more like building a custom race car—every single part is hand-picked for maximum output.
These aren't just isolated pieces. They're designed to work in concert, creating a cohesive system that stamps out the performance bottlenecks and security holes you often find in generic, one-size-fits-all environments.
Let's break down each element.
Enterprise Infrastructure Components Explained
Before diving into the specifics of each component, this table provides a high-level overview of the core building blocks, what they do, and why they matter for your business.
| Component | Primary Function | Key Business Benefit |
|---|---|---|
| Bare Metal Servers | Provides dedicated, single-tenant computing resources (CPU, RAM). | Uncontended, predictable performance for demanding workloads. |
| Colocation | Houses your privately owned hardware in a specialized data center. | Access to enterprise-grade power, cooling, and security you couldn't build yourself. |
| DDoS Mitigation | Filters incoming network traffic to block malicious attacks. | Guarantees service availability and protects against costly downtime. |
| High-Speed Networking | Connects infrastructure and provides optimized global data transit. | Low-latency, high-bandwidth connectivity for a fast user experience. |
| NVMe Storage | Offers ultra-fast data read/write capabilities for applications. | Instant data access, eliminating storage bottlenecks and improving responsiveness. |
This table gives you the "what" and "why." Now, let's explore the "how" for each of these critical components.
Bare Metal Servers: The Dedicated Engine
At the heart of any high-performance setup is pure, unadulterated processing power. That's where Bare Metal Servers come in. They are the custom-built engines, giving you raw, dedicated hardware for one purpose and one purpose only: yours.
Unlike virtual machines, which slice up and share resources among many users, a bare metal server gives you 100% of the CPU, RAM, and storage. This means your application never has to wait in line or compete for resources. This direct hardware access is absolutely critical for workloads that can't tolerate latency or performance swings. For example, a video transcoding service needs every last drop of processing power to encode files quickly. Running on bare metal means it avoids the "hypervisor tax"—the performance overhead from virtualization—ensuring consistently fast speeds.
You can learn more about how dedicated bare metal servers provide this level of uncontended performance for demanding applications.
Colocation: The Secure Vault
Your servers might have all the muscle, but they need a safe and reliable place to operate. Colocation is like having your own private, reinforced vault inside a fortress. You own and control your hardware, but you house it in a specialized data center that handles the enterprise-grade power, cooling, and physical security.
This model gives you the best of both worlds: total control over your gear and access to a facility with redundant systems you could never afford to build on your own. For example, a financial trading firm can place its custom servers in a colocation facility to get direct, low-latency connections to multiple network carriers—a massive advantage where every millisecond counts.
By placing your own hardware in a top-tier data center, you inherit its resilience. This includes A+B power redundancy, advanced fire suppression systems, and 24/7 physical security monitoring—features that guarantee your infrastructure stays online.
DDoS Mitigation: The Elite Security Detail
In today's world, where online threats are a constant reality, powerful protection isn't just nice to have—it's essential. DDoS Mitigation acts as an elite security detail standing guard at the edge of your network. Its only job is to inspect all incoming traffic, spot malicious requests, and stop attacks cold before they can ever touch your servers and knock you offline.
Modern DDoS protection is far more sophisticated than a simple filter. It analyzes traffic on multiple levels (from Layer 3 up to Layer 7) to block everything from huge network floods to tricky application-layer attacks designed to quietly drain your server resources. For instance, an online gaming platform under a targeted attack can keep the game running smoothly for players because all that malicious traffic is scrubbed away, letting only legitimate data through. This always-on defense is a must-have for any service that depends on constant uptime.
High-Speed Networking: The Private Superhighway
The fastest servers on earth are completely useless if their data is stuck in traffic. High-speed Networking is the private superhighway that connects all your infrastructure and links it to the rest of the world. This isn’t your average internet connection; it's a meticulously engineered network built for high bandwidth and minimal delay.
The secret sauce includes redundant connections to multiple internet backbone providers and globally optimized routes that make sure your data always takes the most efficient path. For example, a global SaaS platform for project management can ensure a user in Asia gets the same snappy load times as a user in Europe because the network is smart enough to route their requests around congestion and latency spikes.
NVMe Storage: The Instant Retrieval System
Last but not least, your applications need to access data instantly. Modern Gen 4/5 NVMe Storage is like a lightning-fast retrieval system for your data. It dramatically cuts down the time an application needs to read or write information, which has a huge impact on how responsive your whole system feels.
Picture an e-commerce site with millions of product images and a complex inventory database. With NVMe storage, product pages load almost instantly and inventory checks are seamless, creating a smooth, engaging shopping experience that encourages customers to stick around and make a purchase. This incredible speed comes from the technology’s ability to handle thousands of data requests at once without even breaking a sweat.
Why Top Companies Rely on Custom Infrastructure
One-size-fits-all infrastructure just doesn't cut it for businesses with unique, high-stakes operational pressures. That’s why leading companies in demanding sectors build their digital foundations on custom enterprise infrastructure. They need architectures engineered from the ground up to solve their specific challenges—in worlds where failure simply isn't an option.
For these organizations, infrastructure isn't just another line item on a budget; it's a genuine competitive advantage. It directly impacts revenue, customer loyalty, and their reputation in the market. Whether it's guaranteeing a flawless experience for millions of gamers or safeguarding sensitive financial data, having the right infrastructure makes all the difference.
SaaS Platforms Meeting Demanding SLAs
Software as a Service (SaaS) platforms are built entirely on trust. Customers sign up expecting the service to be available and performing perfectly whenever they need it. To uphold their end of the bargain and meet strict Service Level Agreements (SLAs), a custom infrastructure is non-negotiable.
For example, a company providing an enterprise CRM platform cannot afford slowdowns. To keep customers happy and loyal, these providers need dedicated servers that deliver consistent, predictable performance. This approach completely avoids the "noisy neighbor" problem common in shared cloud environments. They also rely on redundant, high-speed networks to provide the stable, low-latency connectivity required to serve a global user base. After all, even a minor slowdown can lead to customer churn and serious damage to their brand.
The Low-Latency World of Online Gaming
In the hyper-competitive arena of online gaming, the gap between winning and losing is often measured in milliseconds. For gaming companies, delivering a smooth, fair, and responsive experience is the absolute baseline. This is where low-latency bare metal servers and aggressive DDoS protection become mission-critical.
Bare metal delivers the raw, uncontended processing power needed to handle millions of simultaneous player actions without a hint of lag. This direct, exclusive access to hardware ensures every player gets the same fast connection, eliminating unfair advantages caused by infrastructure bottlenecks.
For a multiplayer game with a global audience, even a fraction of a second of lag can ruin the experience. Always-on DDoS mitigation is equally vital, as gaming servers are frequent targets of attacks designed to disrupt gameplay and frustrate players.
This diagram shows how bare metal, networking, and storage form the core of a high-performance system.
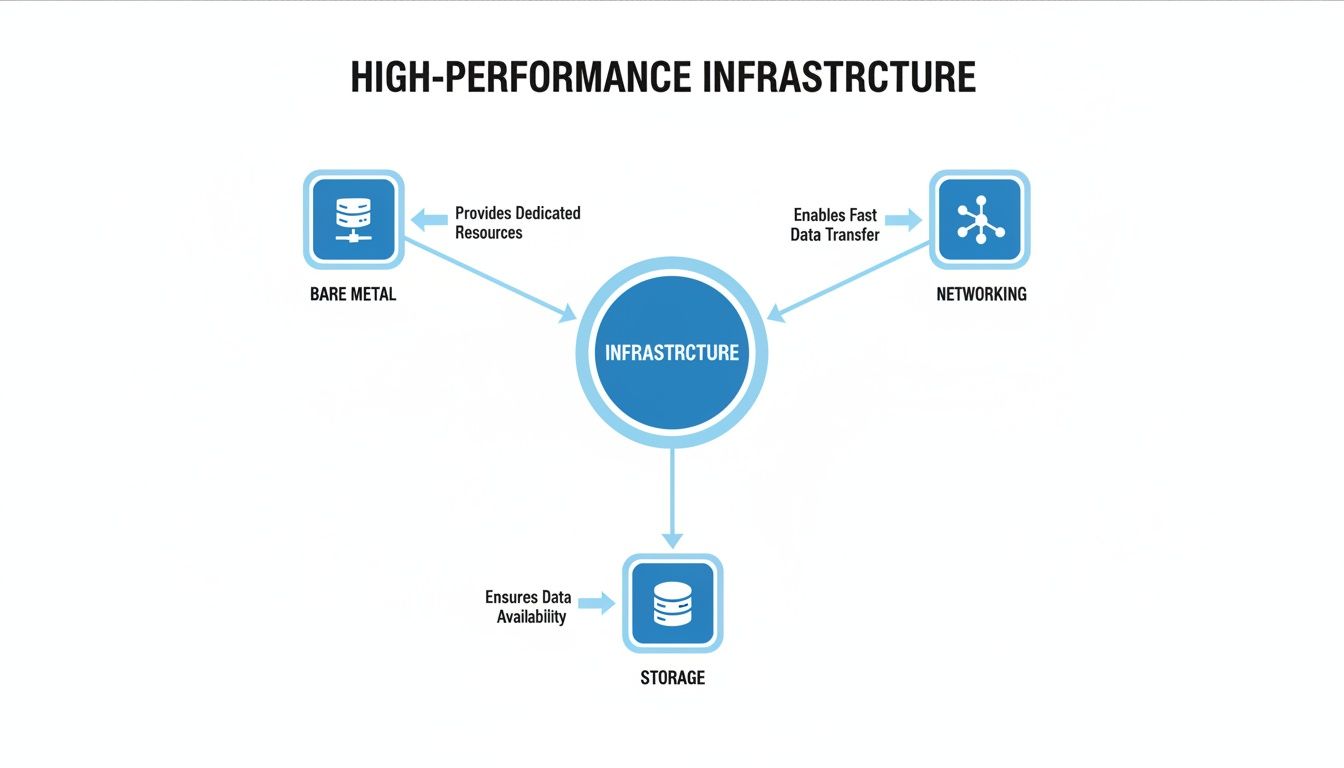
This visualization highlights how these distinct components work together to deliver the reliability and speed necessary for demanding enterprise applications.
Secure Environments for Managed Service Providers
Managed Service Providers (MSPs) stake their entire business on providing rock-solid IT services to their clients. Their reputation hinges completely on the stability and security of the infrastructure they operate, which makes colocation a cornerstone of their strategy.
By placing their own hardware in a secure, carrier-neutral data center, MSPs can build out secure, multi-tenant environments where they have total control. For instance, an MSP specializing in HIPAA-compliant hosting for healthcare clients can use a colocation facility to implement their own custom security controls and physical access policies, giving them the freedom to design bespoke solutions for each client while piggybacking on enterprise-grade power, cooling, and physical security. It’s a model that offers the best of both worlds: control and credibility.
Mission-Critical Applications in Finance and Healthcare
In industries like finance and healthcare, uptime isn't just a goal—it's a regulatory and operational mandate. The mission-critical applications that process financial transactions or manage patient data must stay online 99.99% of the time, or even higher. The fallout from even a brief outage can be catastrophic, leading to massive financial penalties and a total loss of public trust.
These organizations build on resilient architectures with multiple layers of redundancy across power, networking, and servers. A practical example is an online banking portal that uses an active-active, multi-site architecture. This ensures business continuity, even in the face of a hardware failure or a major network event at one of its data centers.
This trend is reflected in the market's growth; the global cloud computing market is projected to top USD 1 trillion by 2028. With 72% of organizations now adopting generative AI, investments in powerful, reliable infrastructure are exploding as enterprises balance on-premise control with hybrid flexibility. You can explore more insights on this shift in IDC's research into enterprise infrastructure.
Choosing the Right Infrastructure Partner
Picking a partner for your enterprise infrastructure is one of the most important decisions you'll make. It’s not a short-term fling; it's a long-term commitment that has a direct line to your performance, your security, and ultimately, your bottom line. You have to look past the flashy marketing and vague promises to find a provider who can actually back up your mission-critical goals.
To really get it right, you need a solid framework for evaluation. It comes down to asking the tough questions and knowing what to look for in the fine print. By focusing on four key pillars—performance, service guarantees, security, and cost—you can build a clear picture of who really has your back.
Evaluating True Performance
Performance isn't just a CPU model number on a spec sheet. Real-world performance comes from the quality and design of the entire hardware stack, from the silicon up. Don't just ask what hardware they have; ask how it’s all put together and kept current.
A provider might boast about a powerful processor, but is it from last year or the year before? Older-generation CPUs can create serious bottlenecks for today's demanding applications. The same goes for storage and networking.
- CPU Generations: Get specific. Ask which Intel or AMD generations they offer. For a high-frequency trading application, having access to the latest processors with the highest clock speeds is non-negotiable.
- Storage Speed: Dig into the details of their NVMe storage. Are you getting faster Gen 4 or Gen 5 drives? For a database-heavy application, the jump in speed can mean a massive improvement in query times.
- Network Capacity: Look beyond a simple bandwidth number. Ask about their total network capacity, who they peer with, and how they optimize global routes. A resilient network with multiple, high-capacity uplinks is what keeps you online and fast for users everywhere.
Understanding Service Level Agreements
A Service Level Agreement (SLA) is the provider's promise to you, but let’s be honest—not all promises are created equal. A 99.99% uptime SLA looks great on paper, but the real test is what happens when they break that promise.
The fine print is where you'll find out how committed they really are. A strong SLA offers meaningful service credits for any downtime, showing that the provider has real skin in the game to keep your services running. For example, if your service goes down for an hour, a weak SLA might give you a credit worth a few dollars, while a strong one might credit you for an entire day's service.
Look very closely at the SLA for exclusions. Some providers will exclude downtime from scheduled maintenance or even certain types of DDoS attacks from their guarantee. That can make the agreement pretty much useless. A partner you can trust will offer a clear, comprehensive SLA with as few exceptions as possible.
Assessing Security and Mitigation
Security isn't an add-on; it's a fundamental requirement for any enterprise setup. When you’re vetting a provider, you need to understand the depth of their security measures, especially when it comes to DDoS attacks.
Basic filtering just doesn't cut it anymore. Modern attacks are sophisticated, hitting both the network (Layers 3-4) and application (Layer 7) levels. Your provider must offer comprehensive, always-on protection that can handle both types of threats without someone needing to flip a switch.
Here’s a practical example: Imagine it's the first day of a huge sale, and your e-commerce site gets hit with a clever application-layer attack that mimics legitimate shopping cart activity. A basic firewall might not even see it. An advanced mitigation system, on the other hand, would spot and block the malicious traffic in seconds, ensuring your real customers can keep shopping without a hitch. That proactive defense is what separates a basic host from a true infrastructure partner.
Analyzing Cost Models and Transparency
Finally, take a hard look at the provider's cost model. The cheapest option upfront is rarely the most cost-effective in the long run. Hidden fees for things like bandwidth overages, support tickets, or extra security features can make your monthly bill balloon unexpectedly.
Find a partner who is upfront and transparent with their pricing. They should be able to clearly explain what’s included in their base packages and what costs extra. For example, does "unlimited bandwidth" really mean unlimited, or is there a fair use policy that could lead to throttling or extra charges? No surprises.
Provider Evaluation Checklist
To help you stay organized during your search, we've put together a simple checklist. This table outlines the critical questions to ask and what a high-quality answer should look like, helping you compare potential partners on the things that truly matter.
| Evaluation Criteria | Key Questions to Ask | What to Look For (Ideal Standard) |
|---|---|---|
| Performance | What CPU generations and NVMe storage options are available? Can you provide benchmarks? | The latest-generation hardware with transparent, verifiable performance benchmarks. |
| SLA | What are the exact terms, credits, and exclusions in your uptime SLA? Is maintenance excluded? | A 99.99% or higher uptime guarantee with meaningful service credits and minimal, clearly defined exclusions. |
| Security | Is DDoS mitigation always-on? Does it cover application-layer (Layer 7) attacks automatically? | Proactive, multi-layer mitigation that is always active and covers Layers 3-7 with sub-second detection. |
| Cost Model | Are there any potential hidden fees for bandwidth, support, or advanced features? Is pricing all-inclusive? | Transparent, straightforward pricing with no surprise charges. All potential costs should be clearly outlined upfront. |
By using this checklist, you can systematically vet each provider and move beyond surface-level claims. The goal is to find a partner who not only meets your technical needs but also aligns with your business values through transparency and a genuine commitment to your success.
Putting the Pieces Together: Resilient and Scalable Architectures
Having powerful hardware is one thing, but how you assemble those pieces is what truly defines an enterprise-grade infrastructure. This is where your DevOps and engineering teams shine, transforming a collection of servers and network gear into a cohesive system that's resilient, scalable, and ready for whatever comes next.
A well-thought-out architecture means a single point of failure won't cripple your entire operation. It also gives you a clear path for growth, letting you add capacity without having to tear everything down and start over. That kind of strategic foresight is the difference between an infrastructure that just keeps the lights on and one that actively drives business forward.
Blending Control with Flexibility in Hybrid Models
One of the most popular and effective patterns we see today is the hybrid infrastructure model. Think of it as getting the best of both worlds: it combines the raw, predictable power of your own dedicated bare metal servers with the on-demand flexibility of the public cloud.
A perfect example is a SaaS company that provides data analytics. They might run their core database—the one processing complex queries that absolutely cannot lag—on a high-performance bare metal cluster to guarantee lightning-fast I/O. Meanwhile, they can spin up cloud VMs for bursty, less critical workloads like dev/test environments or generating monthly customer reports. This mix delivers peak performance where it matters most while keeping things agile and cost-effective elsewhere.
Designing for Continuity with Multi-Site Redundancy
To guarantee real business continuity, you have to architect for failure. Multi-site redundancy is a strategy that does just that by protecting your services from a localized outage, whether it's a fiber cut, a power grid failure, or something worse. The concept is simple: distribute your infrastructure across at least two geographically separate data centers.
Here are the two most common ways to pull this off:
- Active-Passive Failover: One data center (the active site) handles 100% of your live traffic. The second one (the passive site) is a mirror image, standing by and ready to take over in a heartbeat if the primary location fails. It’s a classic, solid approach to disaster recovery. For example, a healthcare provider might use this model for their electronic health record system.
- Active-Active Load Balancing: In this setup, both data centers are live and serving user traffic simultaneously. This not only provides instant failover but also boosts performance by directing users to the data center that's physically closest to them, reducing latency. An e-commerce site with global customers would benefit greatly from this approach.
These designs are non-negotiable for any application that can't afford even a minute of downtime. This level of resilience is becoming even more critical as data center power demands are expected to more than double by 2030, largely due to hungry AI workloads. Providers must be able to deliver architectures with A+B power redundancy and expert support to keep these essential systems humming.
An effective architecture isn't just about surviving failures; it's about making them invisible to your end-users. With proper multi-site redundancy, a major incident at one location becomes a non-event for your customers.
Planning a Smooth Migration and Day 2 Operations
Moving from a shaky environment to a high-performance one is a major project, and success depends on planning for what happens after the move. This is where Day 2 operations—the ongoing work of monitoring, managing, and optimizing—come into play.
A seamless migration begins with a thorough inventory of your applications and all their dependencies. From there, you build a phased rollout plan to move things over with minimal disruption. But once you're live in the new environment, having the right tools for monitoring and out-of-band management is what allows you to stay in control. To ensure your new infrastructure is secure from the moment it goes live, you can explore options like always-on enterprise DDoS protection.
Measuring Success and Optimizing Your Operations
So, you've made a significant investment in your enterprise infrastructure. What now? The real measure of its value isn't just the upfront cost of hardware; it’s about what you get back in operational excellence—less downtime, faster performance, and fewer security-related fire drills.
A truly great infrastructure partner doesn't just hand you servers. They give you a solid foundation to run your business at its absolute best. To see that payoff, you need to track the right numbers and adopt smart habits that keep your environment stable, efficient, and cost-effective for the long haul.
Key Metrics for Measuring Infrastructure ROI
To really understand the impact of your investment, you have to connect the dots between your infrastructure's performance and your business's bottom line. These are the metrics that tell that story.
- Reduced Downtime Costs: Every minute of an outage has a price tag. The math is simple: multiply your average revenue per minute by the total minutes of downtime. A well-designed, resilient architecture can shrink this number to nearly zero, offering a clear and compelling return.
- Improved Application Response Times: Speed directly affects user happiness and conversions. It’s crucial to measure the before-and-after latency for critical user actions. For an e-commerce platform, knocking just 500 milliseconds off a page load can lead to a direct and measurable lift in sales.
- Lower Security Incident Costs: Think about the true cost of a DDoS attack or a breach—the man-hours spent fighting it, the lost revenue, the reputational damage. An always-on DDoS mitigation service turns a potentially catastrophic emergency into a predictable, manageable operational expense.
Operational Best Practices for Peak Efficiency
Running a high-performance environment isn’t about just reacting to problems. It’s about being proactive to stay in control and squeeze every bit of efficiency out of your setup. It's about working smarter, not just harder.
One of the most important things you can do is set up rock-solid monitoring. Use tools that give you a deep, real-time look into server health, network traffic patterns, and how your applications are behaving. By setting up automated alerts for anomalies—like a sudden CPU spike or a weird traffic pattern—your team can jump on potential issues before they ever affect your users.
Another huge win for efficiency comes from leaning on the support services available to you.
Think about it: using remote hands services at your colocation facility is a total game-changer. Instead of flying an engineer across the country for a simple cable swap or a reboot, you can have an on-site expert handle it in minutes. That’s a massive saving in both time and money.
Here’s a quick checklist of core practices to keep your operations running smoothly:
- Establish Comprehensive Monitoring: Put tools in place to track CPU, RAM, network latency, and application-specific KPIs in real time.
- Define Alerting Thresholds: Configure automated alerts that notify your team about performance dips or security events before they snowball into major problems.
- Leverage Out-of-Band Management: Make sure you have secure, independent access to your servers for remote troubleshooting and reboots, especially if the main network goes down.
- Create a Disaster Recovery Playbook: Don't just have a plan—document it and test it regularly. A well-rehearsed failover procedure is your best friend during an actual outage.
At the end of the day, picking the right enterprise solution is a strategic play that pays off in reliability, performance, and growth. It’s about building a foundation that doesn't just support your business now but gives you the operational control to scale with confidence for years to come.
Frequently Asked Questions
Even with the best-laid plans, a few questions always pop up when you're thinking about a move to serious enterprise infrastructure. Let's tackle some of the most common ones I hear from clients to help you get a clearer picture.
Bare Metal vs. Public Cloud VMs
So, what's the real difference between a bare metal server and a standard public cloud VM? It helps to think of it like owning a dedicated race car versus renting a shared shuttle bus. Both will get you down the road, but how they perform is night and day.
A public cloud VM is just a small slice of a much larger physical server. You're sharing the CPU, the RAM, and the network connection with a bunch of other tenants you don't know. That sharing is what causes unpredictable performance—the dreaded "noisy neighbor" effect.
With bare metal, you get 100% of the server's resources. No hypervisor overhead, no resource contention. You get direct, raw access to the hardware, which guarantees the kind of consistent, predictable performance you absolutely need for things like gaming servers, big data processing clusters, or financial trading platforms where every millisecond counts.
Benefits of Carrier-Neutral Colocation
How does "carrier-neutral" colocation actually help my business? In two words: choice and resilience. A carrier-neutral facility isn't locked into a single internet provider. Instead, it’s a marketplace, giving you direct access to dozens of different networks all under one roof.
This opens up some big advantages:
- Get better pricing. When carriers have to compete for your business, you win.
- Fine-tune your performance. You can pick and choose the network provider that offers the absolute best routes to your specific customers.
- Build in real redundancy. By connecting to two or more different carriers, you can ensure that a major outage on one network won't take your business offline.
For example, a global SaaS company can use a carrier-neutral facility to blend different networks to create a custom-tailored solution. This allows them to guarantee super-low latency for their users in Europe, Asia, and the Americas, directly impacting customer satisfaction and making it easier to hit their SLAs.
The Need for Always-On DDoS Mitigation
Do we really need our DDoS mitigation to be "always-on"? For any business where uptime is tied directly to your revenue or reputation, the answer is an unqualified yes. Trying to react to a DDoS attack after it starts is a recipe for disaster. By the time you’ve detected it and scrambled your team, your service is already down.
Always-on mitigation is your front-line defense, constantly watching and cleaning all the traffic heading your way. It spots and drops malicious traffic from even the most massive, sophisticated attacks long before it ever gets a chance to touch your servers. Your real users never even notice a blip. For an online retailer, this means an attack during a major holiday sale is completely neutralized, protecting millions in potential revenue. It effectively turns a potential company-killing crisis into a complete non-event.
Ready to build an infrastructure foundation you can actually count on? The Soraxus team is here to help you architect the right mix of high-performance bare metal, carrier-neutral colocation, and always-on DDoS mitigation. Explore our enterprise infrastructure solutions and lock down your mission-critical applications today.


